Nextbikefahrten in Karlsruhe
Übersicht
- Der Datensatz
- Welche Daten könnte man hieraus ableiten?
- Grobe Visualisierungen
- Praktikabilität ist wichtiger als gesicherte Wahrheit
- Probleme im Umgang mit großen Datenmengen
- Verzeichnis und Infos
Der Datensatz
Zwar ist die API von Nextbike durch einen entsprechenden Schlüssel gesichert, doch wer diesen öffentlich mit in die URLs der eigenen Website schreibt oder die Anforderung eines Keys ebenso simpel ermöglicht, kann sich wohl kaum darauf berufen, dass einem die Vertraulichkeit der Responses wirklich am Herzen liegt.
Frägt man in regelmäßigen Abständen die in einer Stadt verfügbaren Fahrräder ab, so lassen sich hieraus Start- und Endkoordinaten sowie Zeiten ableiten. Auch erfährt man über den Stationsnamen, ob ein Fahrrad an einer Station oder einfach so abgestellt wurde.
Diese Liste an Fahrten kann man beispielsweise wie folgt führen:
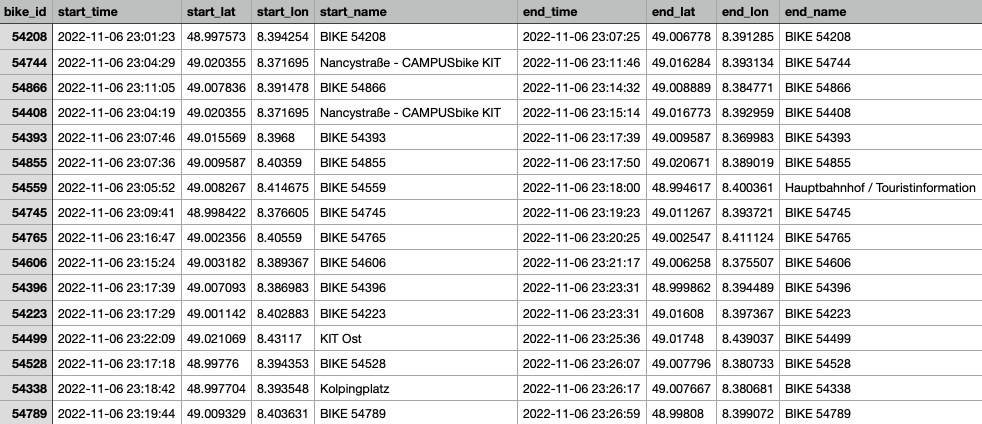
Gesammelt wurden knapp 12.000 Fahrten zwischen dem Abend des 6. und Morgen des 10. Novembers 2022. Beschränken wir uns auf volle Tage, so erhalten wir 11.607 Fahrten über 72h - knapp 3 Räder pro Minute durchschnittlich, zu Stoßzeiten mehr als doppelt so viel.
Welche Daten könnte man hieraus ableiten?
Einerseits lassen sich allgemeine, statistische Auswertungen erstellen, die die Fahrtdauer, Uhrzeiten, Häufigkeit der Nutzung ausgewählter Fahrräder, Fahrten von und zu Stationen, sowie die Entfernung via Luftlinie, umfassen. Andererseits können wir die Daten aber auch mit den in Karlsruhe oder anderen Städten vorhandenen Flexzonen sowie den Koordinaten der Stationen abgleichen und so bspw. wie Nextbike selbst sehen, ob und wie oft Fahrräder außerhalb von Stationen und Flexzonen abgestellt werden und wo Strafgebühren verlangbar sind, aber vielleicht auch sehr gut zeigt, wo Bedarf für neue Stationen herrscht.
Ebenfalls können wir nach Stoß- und Pendelzeiten filtern, was eine detailliertere Auswertung von häufig genutzten Radwegen für die tägliche Anfahrt in die Arbeit oder Uni attraktiv macht. Wer jedoch täglich mit dem Fahrrad pendelt wird sich hierzu aber wohl kaum ein schweres Nextbike nehmen, dessen Verfügbarkeit ebenso wenig garantiert ist wie die Leichtgängigkeit beim Fahren durch bspw. platte(re) Reifen, eine durchspringende Gangschaltung oder rasselnde Tretlager.
Für Karlsruhe sprechen jedoch einige Überlegungen für eine (zukünftige) weitere Auswertung, die nicht so verzerrt sein könnte, wie man vielleicht initial vermutet:
Da Fahrradfahren an Tagen, an welchen es regnen könnte, sehr viel unattraktiver wird, aber für kurze Strecken die Bahn die unflexiblere als auch längere Fahrt darstellt, kann man, da die Fahrradmitnahme zu Stoßzeiten nicht nur unpraktisch sondern auch nicht gestattet ist, auf die Idee kommen, mit dem Nextbike hin oder aber zurück zu fahren und bei Regen auf die Bahn auszuweichen.
Durch eine Querfinanzierung über den Studierendenbeitrag am KIT als auch an der Hochschule Karlsruhe ist zudem die Nutzung für Studierende extrem günstig. Zwar kann man auch mit einem eigenen Fahrrad fahren, durch die große Verfügbarkeit der Räder auf dem Campus ist jedoch besonders die Heim- oder Weiterfahrt attraktiv. Weder ist man gezwungen, das eigene Fahrrad stehen zu lassen und es am nächsten Tag nicht zu haben, noch muss man es für kurze Fahrten, die man am Ende bspw. mit Kommillitoninnen zurückläuft, schieben. Durch das Rahmenschloss hat man zudem die Möglichkeit das Fahrrad schnell und unkompliziert abzuschließen und da es auch nicht das eigene ist, muss man kaum Angst um Schäden im Lack oder Diebstahl haben. Somit ergibt sich eine Grundsituation, die es eher unattraktiv macht, ein eigenes Fahrrad zur Uni zu nehmen, wenn man denn auch gut mit der Bahn zur Uni kommt und die Verfügbarkeit der Räder sehr gut ist. Zwar sind nicht alle Fahrten vom oder zum Campus Pendelstrecken, doch kann man durch das Exkludieren kurzer Fahrten und die oben erwähnten Stoßzeiten eine plausible Fahrtenliste erhalten. Da die detaillierte Auswertung dieses Ansatzes jedoch nicht nur erheblich aufwendiger, sondern auch stochastisch unsicherer ist, sind die Visualisierungen dieser Fahrten in diesem Artikel noch nicht enthalten.
Durch die Flexzone, die sich über die Kernstadt erstreckt, sind jedoch auch alltägliche Routen sehr gut erfassbar und bieten durch die Flexibilität des Abstellorts und die hohe Dichte verfügbarer Fahrräder in der Innenstadt ein wenig verzerrtes Bild häufig angefahrerener Orte.
Grobe Visualisierungen
Verzeichnen wir die Startkoordinaten der Fahrten in einer Karte, so können wir hier zur verbesserten Sichtbarkeit vieler und eng beieinander liegenden Punkten eine Heatmap mittels Kerndichteschätzung erstellen. Dabei wird gezählt, wieviele Punkte im Umkreis einer gewählten Koordinate liegen und dieser Wert zur schnellen und intuitiven Visualisierung anhand einer Farbskala dargestellt.
Verzeichnet sind auf der Karte auch die in Karlsruhe verfügbaren Flexzonen der Kernstadt, des KITs sowie die Flexzone Durlachs im Osten, wobei sich eine starke Überschneidung der Aktivität mit deren Fläche zeigt. Größere Hotspots finden sich allerdings etwa an einem großen Studierendenwohnheim, dem Hadiko, nordöstlich angrenzend an die Flexzone des KITs. Auch die Wohnheime in der Waldstadt, wobei nicht alle eine Station haben, sowie zwei in der Nordstadt sind klar erkennbar.
Eine sehr gleichmäßige Verteilung der Startkoordinaten zeigt sich in der Innenstadt, was, wie oben bereits erwähnt, eine gute Grundlage für wenig verzerrte POIs bietet. Für die Endkoordinaten zeigt sich nahezu dasselbe Bild.
Praktikabilität ist wichtiger als gesicherte Wahrheit
Die gesammelten Daten bieten in dieser Rohform jedoch keine gute Möglichkeit, um häufig befahrene Routen zu finden. Denn die recht homogen in der Innenstadt verteilten POIs lassen keinen Rückschluss über die angefahrene Häufigkeit zu, weil sie nur durch Start- und Endkoordinaten gemessen werden, Fahrräder aber auch auf einer Route von außerhalb und zurück geparkt werden können und sich diese Fälle über die Protokollierung der verfügbaren Räder nicht ergibt. Schließlich sind mittels App als geparkt vermerkte Räder nicht für andere verfügbar. Andererseits liegen die POIs der Innenstadt aber naturgemäß sehr zentral und werden auch auf durchquerenden Routen erreicht. Für die Messung des Verkehrs ist es, besonders im Radverkehr, am Ende nicht relevant, ob ein Ort Ziel oder nur Teil der Route ist. Das erste Problem ist epistemisch schlicht unlösbar, weil die Daten nicht existieren, das zweite Problem lässt sich jedoch durch Annäherung angehen.
Würden wir zwischen Start und Ziel lediglich Orthodrome bzw. Geödäten zeichnen, wäre dies kaum verwertbar.
Zwar können wir nun auch hier die Liniendichte berechnen, doch da auch diejenigen Routen, die in der Praxis weitestgehend identisch sind, in der Darstellung mittels Geodäten nicht unbedingt nah beisammenliegen müssen, ist das keine geeignete Darstellung. In anderen Städten, etwa Heidelberg, die keine Flexzone haben, kann es jedoch eine ähnlich gute Darstellung wie das Einzeichnen realistischer Routen sein, da es nicht so viele Start- und Zielkoordinaten gibt.
Aus diesem Grund der Praktikabilität scheint es mir wesentlich sinnvoller, Daten anzunehmen, die plausibel und für Ortskundige umso realistischer sind als gar keine zu haben. Zwar ist nicht gewährleistet, dass die Berechnung von »optimalen« Fahrradrouten auch tatsächlich denen entspricht, die wirklich gefahren wurden. Ebenso ist es aber auch nicht möglich, nachzuweisen, dass die berechneten Routen falsch sind. Für die Verwendung spricht darum, dass sinnvolles »Raten« besser ist als gar nichts zu haben als auch die Plausibilität, dass, realistische Fahrradwege und damit verbunden sinnvolle Routenberechnung anhand aktueller Kartendaten vorausgesetzt, die berechneten Routen weitestgehend den Routen Ortskundiger und damit hoffentlich den Nutzerinnen der Nextbikes entsprechen.
Zur Routenberechnung verwendet werden die Start- und Endkoordinaten der jeweiligen Fahrten. Diese werden mittels OpenStreetMap-Kartendaten, also den dort hinterlegten Radwegen, und dem OpenRouteService berechnet. Da die API des öffentlichen Servers (verständlicherweise) nur 40 Anfragen pro Minute und maximal 2000 je Tag zulässt, wurden die Routen auf einer eigenen Instanz berechnet.
Hierzu wurde das von OpenRouteService bereitgestellte Dockerimage verwendet und die aktuellen OpenStreetMap-Daten über die GeoFabrik heruntergeladen. Für den OpenRouteService existiert zudem ein QGis-Plugin, mit welchem man die Koordinaten aus den Layern an die OpenRouteService-API übertragen kann. Dabei lässt sich die Antwort auch direkt in einem Geopackage abspeichern und somit später die Liniendichte via QGis berechnen. Der Algorithmus ist hierbei derselbe wie in ArcGIS und für R finden sich ebenfalls die gleichen Implementierungen.
Je häufiger ein Streckenabschnitt in einer Routenberechnung verwendet wird, umso hellgrüner ist er markiert. Einzelne Routen werden der Vollständigkeit halber ebenfalls dargestellt, da so die Dimensionen aller Fahrten auch deutlich werden. Bei der Interpretation der dargestellten Routen muss dabei aber stets der Fokus auf dem Kerngebiet liegen, da die Heatmap auch nur in den Flexzonen hinreichend heterogen ist, um eine unverzerrte Auswahl nahezulegen. Betrachten wir die Hotspots der Wohnheime, so werden sicher auch die Strecken von und zu diesen befahren, jedoch dürften diese durch die große Anzahl von Studierenden unter den Nextbikenutzerinnen überbetont sein. Dass die Studierenden in Karlsruhe einen größeren Teil der Bevölkerung darstellen ist sicher kaum zu bestreiten, ebenso wie ihr Anteil am Radverkehr - ihre Überbetonung der Daten durch die quasi kostenfreie, da qua Studistatus vorhandene Möglichkeit zur Nextbikenutzung, jedoch ebenfalls nicht.
Strecken zu Hochschulen und Universitäten können darum hier auch im Vergleich zu den sonstigen Routen stärker dargestellt sein als sie es in Realität sind. Dass die Routenberechnung zudem nicht immer richtig ist, zeigt sich an einer typischen Route vieler Studierender vom KIT Campus zum Wohnheim HaDiKo.
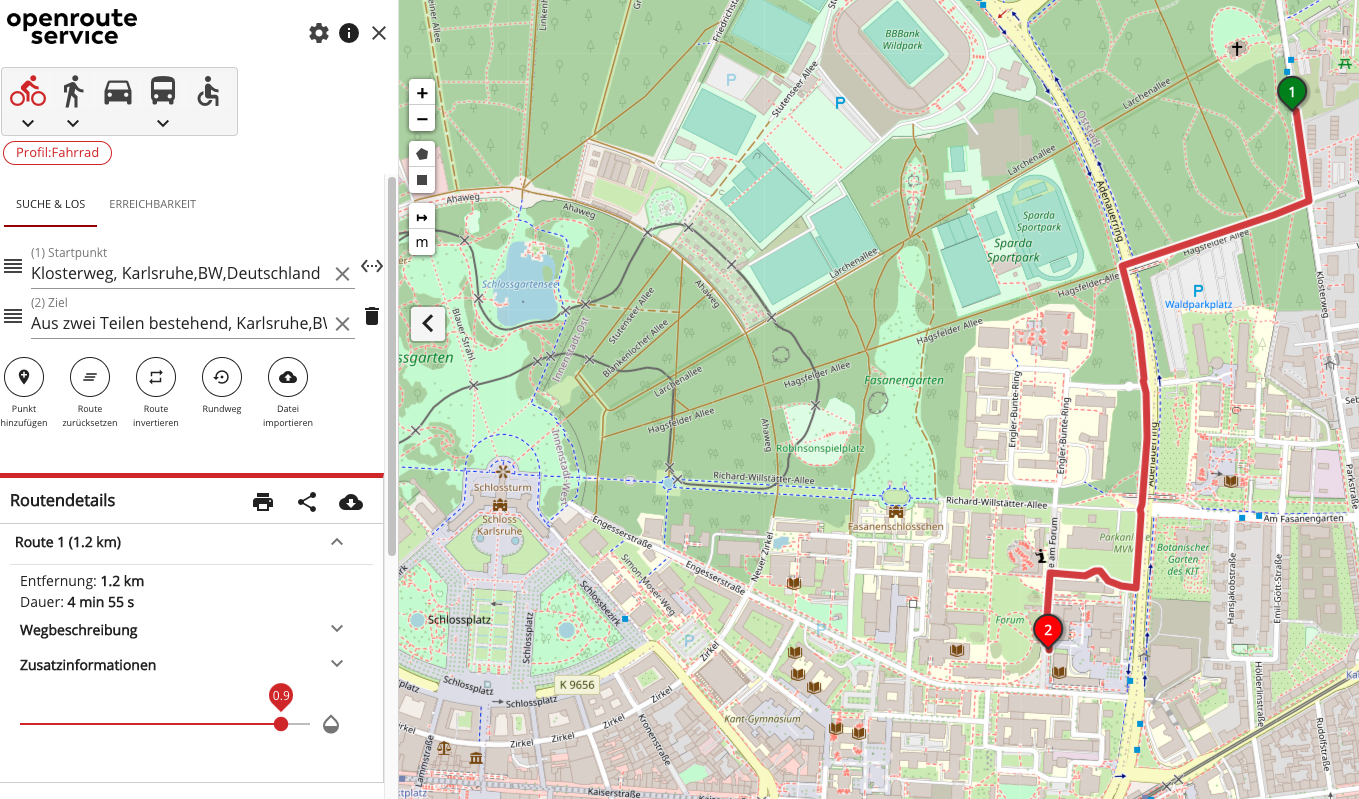
Angesichts der Route entlang des Adenauerrings ist mir unklar, weshalb diese von der lokalen Instanz bei den Berechnungen nicht bevorzugt wurde.
Die Routen über den Schlossgarten, entlang dem Zirkel, der Weg über die Erbprinzenstraße zum Rondellplatz und die Markgrafenstraße hingegen decken sich stark mit eigenen Erfahrungen. Der Umstand, dass Parkhäuser in der Innenstadt zwar prinzipiell verfügbar, aber durch die Anbindung der zwei großen Parkhäuser am Ettlinger Tor und der Badischen Landesbibliothek, erheblich weniger genutzt werden, ist hierbei sicher mitverantwortlich. Forciert wird das auch durch die Sperrung von manchen Verbindungsstraßen durch Poller oder Durchfahrtsverbote für Kraftfahrzeuge, sodass man mit dem Auto immer über vielbefahrene und große Straßen wie die Kriegsstraße fahren muss, was durch Ampelschaltungen einen großen Zeitaufwand mit sich bringt. Mit dem Fahrrad hingegen sind die Strecken ohne weitere Hindernisse oder Regelungen durchfahrbar, was auch die Routenberechnung über die Wald- und Sophienstraße, die eine gute Verbindung in die Weststadt ermöglichen, zeigt.
Folgt man den vorgeschlagenen Routen, so ist die Fahrt über die Hirschstraße durch die Überquerung der Kriegsstraße aktuell allerdings eine eher nervige Angelegenheit. Zur Verbindung der Südstadt mit dem Rest der Stadt nördlich der Kriegsstraße, die als Autoroute nunmehr zwar untertunnelt, jedoch für Fahrräder immer noch sehr hindernd ist, wären Verbindungsbrücken, wie die mittlerweile abgerissene und durch Ampelschaltungen ersetzte auf Höhe der Ritterstraße, wünschenswert.
Probleme im Umgang mit großen Datenmengen
Wie man sich sicher vorstellen kann, ist der Weg zu diesen aufbereiteten Visualisierungen nicht ohne Rückschläge und Unverständlichkeiten bestritten worden.
Dabei stößt man oftmals auf eine Prinzipienfrage: Pfuschen oder sich im systematischen Verstehen versuchen und den Fehler an der Quelle beseitigen?
Dabei ist für die Entscheidung besonders relevant: Wie kritisch ist der aktuelle Fehler für das Vorankommen im Gesamtprojekt und baut man in Zukunft auf den Ergebnissen auf?
Während es etwa für QGis kein Problem darstellt, tausende Punkte, Linien und komplexe Polygone performant darzustellen, so ist der Umgang mit langen Listen und der Verarbeitung und Zusammenfassung mehrerer tausend Werte und Layer ein größeres Problem. So ist Python unglaublich praktisch, andererseits aber auch langsam. Selbst dann, wenn Algorithmen - wie der zur Berechnung der Liniendichte etwa - durch kompilierte und in C oder C++ geschriebene Bibliotheken implementiert sind, ist die Schnittstelle immer noch Python und kann bei einigen hundert Argumenten noch funktionieren. Bei tausend oftmals auch noch, aber beim Versuch, über zehntausend Routen zu berechnen, klappt irgendwas dann aber doch nicht. Im Falle des OpenRouteService-Plugins bspw. liegt die magische Grenze des Routen-in-einem-Layer-Zusammenfassens bei etwas über 3000, beim QGis-eigenen Plugin bei etwa 1600.
Für ein Projekt wie dieses hier, wo es (noch) nicht um die schnelle Erstellung einer immer neuen und aktuellen Auswertung geht, ist es angesichts des Aufwands sinnvoller, den einfacheren Weg zu gehen als zu versuchen, sich in Unbekanntes einzuarbeiten, wenn man den Zeitaufwand nicht abschätzen kann und ihn gegen höhere Berechnungszeit zu tauschen. Beim Zusammentragen der Antworten vom OpenRouteService-Server hätte ich dabei folgende Möglichkeiten gehabt:
- Den Eingabelayer aufteilen und anstatt der Reihe nach knapp 12k Anfragen zu schicken, sondern bspw. 1000 Einträge je Layer und der Reihe nach 12 Layer
- Oder die integrierte Funktion des Plugins nutzen, das je Anfrage einen eigenen neuen Layer mit der Route erstellt. Option 1 ist zwar je zu berechnender Route erheblich schneller, bedeutet aber, entweder händisch 12 Layer zu erstellen oder ein Skript zu schreiben, das die 12 Layer automatisch erstellt bzw. die Eingabedaten so aufteilt, dass man durch die Importierung 12 Layer erstellt, die man der Reihe nach entweder mit dem Plugin aufruft oder aber ein weiteres Skript schreibt, das die Layer der Reihe nach verarbeitet. Die fertigen 12 Routenlayer hätte man dann aber auch wieder zu einem einzigen zusammenfügen müssen, um eine Liniendichteberechnung mit integrierten Funktionen durchzuführen.
Im Falle von Option 2 dauert es dadurch, dass immer wieder ein neuer Befehl gestartet wird, die Anfrage abgewartet, verarbeitet und einzeln abgespeichert wird ca. 3x länger, alle Routen zu berechnen. Andererseits ist der Prozess aber zuverlässiger, da im Falle eines Fehlers keine bereits erstellten Daten verloren gehen. Ebenfalls muss man keine Zeit mit der Erstellung mehrerer Skripte verbringen. Dabei geht es im Falle von Option 1 zwar schneller, sämtliche Routen zu berechnen - bis aber so viele Routen berechnet wurden, dass das Plugin abstürzt, vergehen trotzdem einige Minuten. Man kann also auch die Zwischenzeit nicht anders nutzen, sondern muss den Prozess stetig überwachen.
Am Ende knapp 12k berechnete Routen in jeweils einzelnen Layern in einen großen zusammenzuführen stellte sich allerdings auch nicht als allzu einfach heraus. Denn wie oben erwähnt ist die Menge an Argumenten begrenzt und die Generierung einer Argumentliste über die grafische Oberfläche auch nicht ressourceneffizient. Sollte zudem der Datensatz zukünftig erweitert werden, würde es umso mühseliger, hier keinen schnellen Weg zur Zusammenführung zu haben. Somit habe ich ein Skript erstellt, das die GeoPackage-Dateien, in welchen jeweils ein Layer gespeichert ist, für den entsprechenden Ordner listet und der Reihe nach in variabler Anzahl zusammenführt, wobei die zusammengefassten Layer am Ende erneut verarbeitet werden können. Mit zwei Iterationen je 1000 Eingaben erhält man so am Ende die Möglichkeit bis zu eine Million Dateien in einer zusammenzufassen. Zwar ist dieser Prozess hinsichtlich Hardwareverschleiß durch die Menge der Zugriffe suboptimal, aber erneut korruptionssicherer.
Den einen Layer am Ende erhalten, kann man mit der Liniendichteberechnung starten. Hier gilt es einen Kompromiss zwischen Auflösung und Laufzeit zu finden, da sich Laufzeit und Speicherbedarf, zumindest in den Regionen mit vielen Routen, exponentiell zur Auflösung verhalten.
Das Ergebnis des Prozesses ist eine Bilddatei im GeoTIFF-Format, die anschließend eingefärbt werden kann. Doch auch hier stößt man wieder an die Grenzen so mancher Algorithmen aus dem Baukasten. Zwar bietet QGis von Haus aus die Möglichkeit, sämtliche Werte einem Farbverlauf zuzuordnen, nach einer Klassifizierung aller Werte zeigt sich jedoch der Nachteil einer hohen Auflösung aus dem Prozess davor: Es sind zu viele als dass sie richtig gerendert würden. Das Resultat sind transparente Routen abseits eines kleines Ausschnittes, obwohl ihnen eigentlich eine Farbe zugewiesen wurde.
Die Option, einfach nur n-Gradiente mit linearem Abstand zu wählen ist andererseits auf 255 Werte beschränkt und so ergibt sich erneut die Notwendigkeit eines kleinen Skripts. Prinzipiell ist es dann mittels Bibliotheken wie Matplotlib auch möglich, eine nicht lineare Verteilung, den Rohdaten entsprechend, zu wählen. Für diesen »kleinen« Datensatz schien es nun am Ende aber doch am praktischsten, wenige Abstufungen zu wählen, weil das Endresultat eine irrelevant genaue Darstellung ist und Straßen, die dennoch wichtig und vielbefahren sind, aber von der Routenberechnung nicht gleichermaßen bevorzugt wurden, unterrepräsentiert sind.
Verzeichnis und Infos
Zugehörige Dateien und SHA1-Hashes:
- Fahrten.png (4dc2efc0e9b8178955bbd7d0a56898b76cb24bb0)
- Heatmap-Startkoordinaten.jpg (8be46646654966966d6083494495217c45f207b3)
- Geflecht.jpg (f22a596ebd7dc6ae79f8c3c800021027aa12febc)
- Fahrradrouten-Karlsruhe.jpg (d1af7fb5394311b9dea282130a81fd7f9e3e434)
- Openrouteservice-Screenshot.png (83daa03e88f6727de3d8173efd6ad230a2ffa5b9)
Zur Arbeit
Diese Ausarbeitung wurde im Rahmen der Schlüsselqualifikation »Visualisierungen - Von Daten die Bilder werden wollen« von mir, Patrick Zauner, erstellt.